My tryst with FF Schema continues. In this edition it is the optional field settings that I will be tackling. I have a positional file with following structure.
A 123 456 789
B 735 323 456
C 824 359 531
A occurs 1 to unbounded
B occurs 0 to unbounded
C occurs 0 to unbounded
For optional group (B and C) I created a delimited level and made nillable = "true" and minoccurs ="0". I did same settings for positional group. I am not sure if it required at both levels so I did as a safety measure.
Now for some reasons, C started acting like an optional record but NOT B. I tried playing around with delimiter settings etc but nothing worked. Then I thought of change parser optimization property at root element. Default is "speed" and I changed it to "complexity" and bingo it worked. It seems that default parser setting did not recognize Min occurs ="0". But it is strange as it worked for C level.
I Googled the issue and I found out that people faced the same issue and did what I did. If only, I would have seen these sites before. I would have saved a DAY!
Tuesday, September 19, 2006
Tuesday, August 29, 2006
Flat File Schema and Early Termination
For those who have worked with Flat File Schemas, must have used or at least heard the property called "Early Termination". This Property is exposed with Biztalk SP2 but otherwise it can only be edited using Text editor. There is some kind of confusion as if what happens if the "Early Termination" is set to True.
Let me illustrate it with an example:
Suppose FF schema have 5 fields (A,B,C,D and E) and each 10 in length. The file looks something like:
AAAAAAAAAABBBBBBBBBBCCCCCCCCCCDDDDDDDDDDEEEEEEEEEE.
Now if we set up "Early Termination" as True. The following scenarios are parsed properly and rest fail in Biztalk schema.
1)AAAAAAAAAABBBBBBBBBBCCCCCCCCCCDDDDDDDDDDEEEEEEE (Parsed)
2) AAAAAAAAAABBBBBBBBBBCCCCCCCCCCDDDDDDDDDDE(Parsed)
3) AAAAAAAAAABBBBBBBBBBCCCCCCCCCCDDDDDDDDDD (Not Parsed)
4) AAAAAAAAAABBBBBBBBBBC CCCCCCCDDDDDDDDDDE (Parsed)
So this property only allows flexibility for the last field in the schema.
I faced a situation in a project where Source system sent a file that looked something like:
AAAAAAAAAABBBBBBBBBBCCCCCCCCCCDDDDDDD
It sent less than 5 fields (say 4) and the last field in the file (not in the schema) was partially or completely filled. In Either scenario it will be rejected. Problem was that Source System was very inflexible and would not change the file to suit Biztalk parsing needs.
There were different options that I thought of. I knew that we have to pad the file but question was how to do that. Since Biztalk schema does not pad the incoming file but only pads the outgoing file. And we were receiving the file so we could not use padding.
The other option was do create a pipeline component that would read the stream and pad it before it hits the Biztalk FF schema. Or create some kind of pre processor (windows service) that would do that padding while reading the stream.
It seemed as stream manipulation would be the only way to get around this issue but I wanted to avoid it as I am not a BIG fan of stream manipulation because of inherent dangers associated with it.
So, I thought hard and it clicked to me that I could use the padding property of Biztalk schema to achieve what I needed. All I need to do is to turn the padding property "inside out". In other words. I did the following:
1) Created a simple orchestration with one receive and send shape.
2) Defined a schema with one element only. This way one can take 5 fields together as single field and then use padding property to pad from the last position of incoming field to the maximum positional; length of the complete record in the schema. 50 in our case.
3) In the schema set Padding as Left justified and use Hexadecimal value of "Tab".
4) Define a single message with above schema
5) Create a send pipleline that refers to this single schema with padding.
6) Recv and Send Port will refer to same message.
Complete the orchestration and then drop the file. For a file like:
AAAAAAAAAABBBBBBBBBBCCCCCCCCCCDDDDDDD
The output will be padded to complete length of 50.
Then run this file through original FF schema with 5 fields. It will be parsed properly and will give you the right XML.
Let me illustrate it with an example:
Suppose FF schema have 5 fields (A,B,C,D and E) and each 10 in length. The file looks something like:
AAAAAAAAAABBBBBBBBBBCCCCCCCCCCDDDDDDDDDDEEEEEEEEEE.
Now if we set up "Early Termination" as True. The following scenarios are parsed properly and rest fail in Biztalk schema.
1)AAAAAAAAAABBBBBBBBBBCCCCCCCCCCDDDDDDDDDDEEEEEEE (Parsed)
2) AAAAAAAAAABBBBBBBBBBCCCCCCCCCCDDDDDDDDDDE(Parsed)
3) AAAAAAAAAABBBBBBBBBBCCCCCCCCCCDDDDDDDDDD (Not Parsed)
4) AAAAAAAAAABBBBBBBBBBC CCCCCCCDDDDDDDDDDE (Parsed)
So this property only allows flexibility for the last field in the schema.
I faced a situation in a project where Source system sent a file that looked something like:
AAAAAAAAAABBBBBBBBBBCCCCCCCCCCDDDDDDD
It sent less than 5 fields (say 4) and the last field in the file (not in the schema) was partially or completely filled. In Either scenario it will be rejected. Problem was that Source System was very inflexible and would not change the file to suit Biztalk parsing needs.
There were different options that I thought of. I knew that we have to pad the file but question was how to do that. Since Biztalk schema does not pad the incoming file but only pads the outgoing file. And we were receiving the file so we could not use padding.
The other option was do create a pipeline component that would read the stream and pad it before it hits the Biztalk FF schema. Or create some kind of pre processor (windows service) that would do that padding while reading the stream.
It seemed as stream manipulation would be the only way to get around this issue but I wanted to avoid it as I am not a BIG fan of stream manipulation because of inherent dangers associated with it.
So, I thought hard and it clicked to me that I could use the padding property of Biztalk schema to achieve what I needed. All I need to do is to turn the padding property "inside out". In other words. I did the following:
1) Created a simple orchestration with one receive and send shape.
2) Defined a schema with one element only. This way one can take 5 fields together as single field and then use padding property to pad from the last position of incoming field to the maximum positional; length of the complete record in the schema. 50 in our case.
3) In the schema set Padding as Left justified and use Hexadecimal value of "Tab".
4) Define a single message with above schema
5) Create a send pipleline that refers to this single schema with padding.
6) Recv and Send Port will refer to same message.
Complete the orchestration and then drop the file. For a file like:
AAAAAAAAAABBBBBBBBBBCCCCCCCCCCDDDDDDD
The output will be padded to complete length of 50.
Then run this file through original FF schema with 5 fields. It will be parsed properly and will give you the right XML.
Saturday, July 15, 2006
Validating an Instance in Biztalk
How can one validate an instance of the input file and ensure that the required fields needed for business process are present, data type is correct and min/max lengths are conformed with. This is done to filter “junk” data going into Business Database and to maintain Database Integrity. Further if one needs to catch the errors and populate a database it becomes even more complicated. So what can be done?
Biztalk 2004 has no ability to validate instance on the fly and accumulate errors at once. But, Dot Net offers “SchemaValidation” class to validate the input instance and errors that are trapped can be accumulated and passed as a string through a stored procedure to a SQL/Oracle database. This is how it works.
1. Pass “Instance” and the “Schema” to the schema validation class.
a. Instance is the sample XML message that is to be validated.
b. Schema is the xsd schema that will contain all the information about the required fields, data types, lengths etc.
2. Creating the “tight” schema is a tedious process especially if the file is long. Each field has to be selected and the properties set.
a. For required fields.
i. String type: Set following properties in schema
1. Base Data Type : string
2. Derived by: Restriction
3. Nillable : False
4. Min Occurs: 1 (empty is 1 too)
5. Max length = as required
6. Min length = 1
ii. Date type:
1. Base Data Type : Date
2. Derived by: Restriction
3. Nillable : False
4. Min Occurs: 1 (empty is 1 too)
iii. Integer type
1. Base Data Type : Integer
2. Derived by: Restriction
3. Nillable : False
4. Min Occurs: 1 (empty is 1 too)
5. Max Facet value = as required
6. Min Facet value = as required
b. For optional fields
i. String:
1. Base Data Type : string
2. Derived by: Restriction
3. Nillable : True
4. Min Occurs: 0 (empty is 1 too)
5. Max length = as required
6. Min length = 0
ii. Date Type:
1. Base Data Type : date
2. Derived by: List
3. Nillable : True
4. Min Occurs: 1 (empty is 1 too)
iii. Integer type
1. Base Data Type : Integer
2. Derived by: List
3. Nillable : True
4. Min Occurs: 1 (empty is 1 too)
Note: Decimal Types follow same rules as Integer types. It is not possible to control the lengths for Decimal and Integer OPTIONAL fields from Biztalk schemas. To do this use .Net class that can read the length and validate it in next stage and reject or accept depending on the results.
3. After this “tight” schema is created put this in a folder. Do NOT forget to append a namespace to this schema before passing it in the .Net class. The .Net Class will not work without namespace.
Biztalk 2004 has no ability to validate instance on the fly and accumulate errors at once. But, Dot Net offers “SchemaValidation” class to validate the input instance and errors that are trapped can be accumulated and passed as a string through a stored procedure to a SQL/Oracle database. This is how it works.
1. Pass “Instance” and the “Schema” to the schema validation class.
a. Instance is the sample XML message that is to be validated.
b. Schema is the xsd schema that will contain all the information about the required fields, data types, lengths etc.
2. Creating the “tight” schema is a tedious process especially if the file is long. Each field has to be selected and the properties set.
a. For required fields.
i. String type: Set following properties in schema
1. Base Data Type : string
2. Derived by: Restriction
3. Nillable : False
4. Min Occurs: 1 (empty is 1 too)
5. Max length = as required
6. Min length = 1
ii. Date type:
1. Base Data Type : Date
2. Derived by: Restriction
3. Nillable : False
4. Min Occurs: 1 (empty is 1 too)
iii. Integer type
1. Base Data Type : Integer
2. Derived by: Restriction
3. Nillable : False
4. Min Occurs: 1 (empty is 1 too)
5. Max Facet value = as required
6. Min Facet value = as required
b. For optional fields
i. String:
1. Base Data Type : string
2. Derived by: Restriction
3. Nillable : True
4. Min Occurs: 0 (empty is 1 too)
5. Max length = as required
6. Min length = 0
ii. Date Type:
1. Base Data Type : date
2. Derived by: List
3. Nillable : True
4. Min Occurs: 1 (empty is 1 too)
iii. Integer type
1. Base Data Type : Integer
2. Derived by: List
3. Nillable : True
4. Min Occurs: 1 (empty is 1 too)
Note: Decimal Types follow same rules as Integer types. It is not possible to control the lengths for Decimal and Integer OPTIONAL fields from Biztalk schemas. To do this use .Net class that can read the length and validate it in next stage and reject or accept depending on the results.
3. After this “tight” schema is created put this in a folder. Do NOT forget to append a namespace to this schema before passing it in the .Net class. The .Net Class will not work without namespace.
Thursday, May 25, 2006
Creating FF Schemas in Biztalk - A Different Approach
One of my projects requires integrating a file from a Bank into our financial system. The Bank file is a positional flat file with 8 records. The structure is as follow:
1 – File header
......2 – Transaction header
................5 – Voucher Line
................5A – Distribution Line
................5B - Vchr Tax Line
.......7 – Transaction trailer
8 – File Trailer
All the records can occur multiple times in the file. In past, I always had problems creating FF schemas for positional files especially in area of looping. Surprisingly the approach I took this time made it very easy . I will try to break it down in small easy steps:
I will not go in details of "postional" record entry but focus only on "Looping"
1) I used the “Bottoms-Up” approach (this is what I call it). I broke the file into smaller segments and designed starting from the deepest child element and then added other elements as I moved towards the top. i.e Record 5 to Record 1. And then I designed for rest of the file. i.e Record 5 to Record 8.
2) I first designed the schema for only Record 5. I assumed that the file has only 3 records that can repeat multiple times within a root level. The structure looks something like:
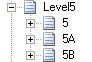
5, 5A and 5B are the positional records that repeat multiple times. So they will have to be under a “delimited” record that has max occurs as “unbounded”. This delimited record will have name “Level5” and Child Delimiter type as "Default Child Delimiter" and Child Order as "Infix". I used the same properties for all the "Delimited" levels.
3) Having designed Level 5, I then designed Record 2 . I followed the same principle. Since Record 2 is parent of Record 5, I placed it one level higher than Record 5 but at the same level as the delimited record “Level5”. Record 2 is positional record like Record 5 and can occur multiple times. So it will again go under “delimited” record that has properties as “unbounded”. We will name it as “Level7_2”. As it shared by Record 2 and Record 7 as we will see later.
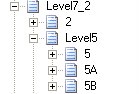
4) I followed the same logic with Record 1 that is parent of Record 2.
5) Having completed the “Middle to Top” path, I started symmetrically copying the same looping from “Middle to Bottom” to get the entire structure which will look like:
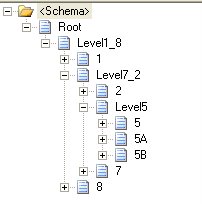
6) At end do not forget to add 1 root delimited record (Root) above Level1_8 that will occur as Single.
7) The last important thing is to set up the properties of the “Schema” node as below:
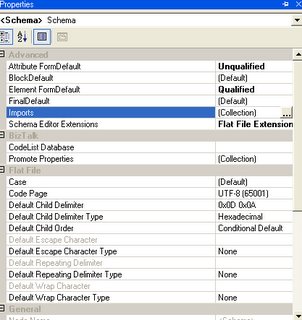
1 – File header
......2 – Transaction header
................5 – Voucher Line
................5A – Distribution Line
................5B - Vchr Tax Line
.......7 – Transaction trailer
8 – File Trailer
All the records can occur multiple times in the file. In past, I always had problems creating FF schemas for positional files especially in area of looping. Surprisingly the approach I took this time made it very easy . I will try to break it down in small easy steps:
I will not go in details of "postional" record entry but focus only on "Looping"
1) I used the “Bottoms-Up” approach (this is what I call it). I broke the file into smaller segments and designed starting from the deepest child element and then added other elements as I moved towards the top. i.e Record 5 to Record 1. And then I designed for rest of the file. i.e Record 5 to Record 8.
2) I first designed the schema for only Record 5. I assumed that the file has only 3 records that can repeat multiple times within a root level. The structure looks something like:
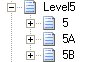
5, 5A and 5B are the positional records that repeat multiple times. So they will have to be under a “delimited” record that has max occurs as “unbounded”. This delimited record will have name “Level5” and Child Delimiter type as "Default Child Delimiter" and Child Order as "Infix". I used the same properties for all the "Delimited" levels.
3) Having designed Level 5, I then designed Record 2 . I followed the same principle. Since Record 2 is parent of Record 5, I placed it one level higher than Record 5 but at the same level as the delimited record “Level5”. Record 2 is positional record like Record 5 and can occur multiple times. So it will again go under “delimited” record that has properties as “unbounded”. We will name it as “Level7_2”. As it shared by Record 2 and Record 7 as we will see later.

4) I followed the same logic with Record 1 that is parent of Record 2.
5) Having completed the “Middle to Top” path, I started symmetrically copying the same looping from “Middle to Bottom” to get the entire structure which will look like:

6) At end do not forget to add 1 root delimited record (Root) above Level1_8 that will occur as Single.
7) The last important thing is to set up the properties of the “Schema” node as below:

Friday, April 28, 2006
"Debugging is not supported under current trust level settings"
If you get the following error while trying to open ASP.net page on the host server.
"Debugging is not supported under current trust level settings"
You will also get 500 error if you hit this page using HTTP POST method from any other machine. This is what you do:
Open the web.config file for the ASP solution and add the "BOLD" text below.
(opening tag)system.web(closing tag)
(opening tag)trust level="Full" originUrl="" (closing tag)
"Debugging is not supported under current trust level settings"
You will also get 500 error if you hit this page using HTTP POST method from any other machine. This is what you do:
Open the web.config file for the ASP solution and add the "BOLD" text below.
(opening tag)system.web(closing tag)
(opening tag)trust level="Full" originUrl="" (closing tag)
Friday, April 07, 2006
Biztalk Server 2006 Clinic- Summary
I attended the Biztalk 2006 clinic on Wed 4 th April at MSFT Office in Iselin,NJ. It was very informative. I left wanting to know more about BAM though. For some reasons it feels as there is so much that can be done with this tool. But lack of documentation always gets me. I have tried my hand on it and honestly I do not feel it very flexible and intuitive. BAM portal addition in 2006 is certainly a positive step. Acceptance of BAM by Biztalk community can dramatically increase the value offered by Biztalk. As a Business user nothing is better than able to use BAM. I scribbled some notes from the clinic that I am posting. These notes came handy while making a presentation to my team.
---------------------------
The presentation started with videos of some companies that are using Biztalk 2004 at present and how they are benefiting from it:
1) INVENSYS: Uses for manufacturing plant
2) Balboa: Financial/Insurance Company
These companies’ uses “Rules Engine” that enables Managers/Operational people to change the variables based on scenarios. This provides them with flexibility
Showed Funny Video We-SYP (We share ur pain).
First Speaker: Sai Prakash from MSFT
Managing and Monitoring:
Tools:
1) Admin Console : General Managing of Applications (Deploying, Enlisting, Starting etc)
2) Microsoft Operation Manager (MOM): For IT monitoring i.e can be used to put alerts to perform specific tasks in event of error. Example being “Contact John Doe if certain error happens”. In short it can be used as knowledge database
3) BAM: This is highest level of monitoring that is intended for a business user.
Tasks that required used of Visual studio for Biztalk 2004 can be performed from Admin Console for 2006 in a very efficient manner. Concept of Application is THE thing in this new version. Each solution can be named as an Application and then all the related artificats like Orchestrations, Maps, Schemas, Pipelines, Non- Biztalk assemblies and Ports can be added under this. Once this is done a single right click on the Application to start will do all of the following:
1) GAC the Non-biztalk assemblies
2) Deploy the Biztalk assemblies
3) Enlist and Start the orchestrations.
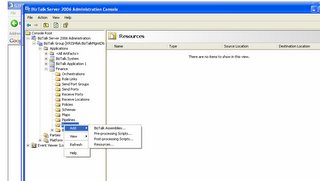
Developer can create MSI packages from Admin console and send them to Admins. Admins just need to import these MSI packages and run and the whole application is installed. The only step left is a right click that starts the application.
So no Need for Deployment Wizard or Batch files for deploying
One can even include a batch file (pre processing script) to create folders in case they need to be created while deploying to a new machine.
The new console will give a snapshot of all errors on per application basis. Further information about the error can be then obtained by simply clicking on the link for errors.
There is a new Role added called IT-OP. This gives same privileges like Admins but READ only. This also shields any sensitive financial/hipaa information that need not be seen across the board.
Another feature is subscribing to errors in the pipelines. Subscription can be based both on Content and Context. There can be a orchestration that sends these errors as an email to the concerned people in a “InfoPath Form” like format. The concerned people can then rectify the error that is causing the error and then send the message back to biztalk and resume the processing
Sai showed a simple demon by setting up and recv and send port. He then stopped the send port and dropped the messages. He then opened the Admin console and we could see the 15 error messages (corresponding to 15 files her dropped) against the specific application name.
Briefly demonstrated FF wizard.
Second Speaker: Kent Brown (Virtual TS) from CitiHudson group.
He spoke about BAM and how this is the most underutilized aspect of Biztalk. He compared it a performance counter monitor. BAM gives an eagle eye view of the business flow through Biztalk
BAM can tap into the work flow at different points and record the pre selected variables. These variables can be of different types. Like Milestones, Dates, Durations, Content variables (Variables inside the message like PO#, Invoice #).
Three Components: Ascending Hierarchy
1. BAM Activity
2. BAM view (Consolidation of BAM Activity)
3. Observation Model (Consolidation of BAM view and BAM Activity)
In the background, BAM uses OLAP processing. It creates cubes to process data
BAM: Roles and Tools:
Role:
1) Business Analyst: Creates the BAM spreadsheet underlining the variables and parameters he needs to track.
2) IT Pro:
3) Developer: Map these variables to the actual work flow through Orchestra ions, Pipelines etc
Tools:
1) BAM spreadsheet: Open the excel sheet. Go to Add Ins and add BAM.
2) Create BAM Activity and give it a name.
3) Add the variables that will be part of this activity and need to be populated. These can be milestones, duration of even the content from the message.
Use Tracking Profile Editor to map these variables from the Work Flow. i.e. In orchestration. These mapping points can be at send, receive shapes. Some field in the message body. Below is a pic of Editior.
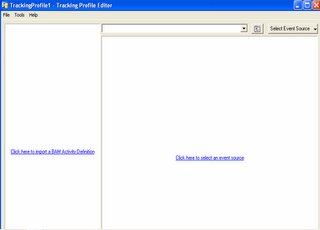
I asked if fields need to be promoted to be accessed while mapping. The answer was NOT NECCESARILY.
BAM can also tap across multiple orchestrations across multiple servers.
He also gave an example how a variable that can change from one application to another can be still represented in the same row. Ie. PO ID: 123 can become SO ID: 246 in marketing application and SHIP ID: 243 in Shipping system. BAM can track this variable through out.
What is new in BAM 2006?
1) Out of box BAM Portal. Runs ASP.Net 2.0
2) Integration with Message Only scenario. i.e if Orchestrations not present in the end to end file process.
3) The BAM portal also has search feature.
---------------------------
The presentation started with videos of some companies that are using Biztalk 2004 at present and how they are benefiting from it:
1) INVENSYS: Uses for manufacturing plant
2) Balboa: Financial/Insurance Company
These companies’ uses “Rules Engine” that enables Managers/Operational people to change the variables based on scenarios. This provides them with flexibility
Showed Funny Video We-SYP (We share ur pain).
First Speaker: Sai Prakash from MSFT
Managing and Monitoring:
Tools:
1) Admin Console : General Managing of Applications (Deploying, Enlisting, Starting etc)
2) Microsoft Operation Manager (MOM): For IT monitoring i.e can be used to put alerts to perform specific tasks in event of error. Example being “Contact John Doe if certain error happens”. In short it can be used as knowledge database
3) BAM: This is highest level of monitoring that is intended for a business user.
Tasks that required used of Visual studio for Biztalk 2004 can be performed from Admin Console for 2006 in a very efficient manner. Concept of Application is THE thing in this new version. Each solution can be named as an Application and then all the related artificats like Orchestrations, Maps, Schemas, Pipelines, Non- Biztalk assemblies and Ports can be added under this. Once this is done a single right click on the Application to start will do all of the following:
1) GAC the Non-biztalk assemblies
2) Deploy the Biztalk assemblies
3) Enlist and Start the orchestrations.

Developer can create MSI packages from Admin console and send them to Admins. Admins just need to import these MSI packages and run and the whole application is installed. The only step left is a right click that starts the application.
So no Need for Deployment Wizard or Batch files for deploying
One can even include a batch file (pre processing script) to create folders in case they need to be created while deploying to a new machine.
The new console will give a snapshot of all errors on per application basis. Further information about the error can be then obtained by simply clicking on the link for errors.
There is a new Role added called IT-OP. This gives same privileges like Admins but READ only. This also shields any sensitive financial/hipaa information that need not be seen across the board.
Another feature is subscribing to errors in the pipelines. Subscription can be based both on Content and Context. There can be a orchestration that sends these errors as an email to the concerned people in a “InfoPath Form” like format. The concerned people can then rectify the error that is causing the error and then send the message back to biztalk and resume the processing
Sai showed a simple demon by setting up and recv and send port. He then stopped the send port and dropped the messages. He then opened the Admin console and we could see the 15 error messages (corresponding to 15 files her dropped) against the specific application name.
Briefly demonstrated FF wizard.
Second Speaker: Kent Brown (Virtual TS) from CitiHudson group.
He spoke about BAM and how this is the most underutilized aspect of Biztalk. He compared it a performance counter monitor. BAM gives an eagle eye view of the business flow through Biztalk
BAM can tap into the work flow at different points and record the pre selected variables. These variables can be of different types. Like Milestones, Dates, Durations, Content variables (Variables inside the message like PO#, Invoice #).
Three Components: Ascending Hierarchy
1. BAM Activity
2. BAM view (Consolidation of BAM Activity)
3. Observation Model (Consolidation of BAM view and BAM Activity)
In the background, BAM uses OLAP processing. It creates cubes to process data
BAM: Roles and Tools:
Role:
1) Business Analyst: Creates the BAM spreadsheet underlining the variables and parameters he needs to track.
2) IT Pro:
3) Developer: Map these variables to the actual work flow through Orchestra ions, Pipelines etc
Tools:
1) BAM spreadsheet: Open the excel sheet. Go to Add Ins and add BAM.
2) Create BAM Activity and give it a name.
3) Add the variables that will be part of this activity and need to be populated. These can be milestones, duration of even the content from the message.
Use Tracking Profile Editor to map these variables from the Work Flow. i.e. In orchestration. These mapping points can be at send, receive shapes. Some field in the message body. Below is a pic of Editior.
I asked if fields need to be promoted to be accessed while mapping. The answer was NOT NECCESARILY.
BAM can also tap across multiple orchestrations across multiple servers.
He also gave an example how a variable that can change from one application to another can be still represented in the same row. Ie. PO ID: 123 can become SO ID: 246 in marketing application and SHIP ID: 243 in Shipping system. BAM can track this variable through out.
What is new in BAM 2006?
1) Out of box BAM Portal. Runs ASP.Net 2.0
2) Integration with Message Only scenario. i.e if Orchestrations not present in the end to end file process.
3) The BAM portal also has search feature.
Tuesday, March 28, 2006
Migration from Biztalk 2004 to Biztalk 2006
I recently converted a Biztalk 2004 project to Biztalk 2006. Believe me this time MSFT is right when they say that "Migration is very Simple". From my experience, all the orchestrations, pipeline, schemas and Maps (All Biztalk Artificats) were migrated without any changes. Some changes were required for some of the .Net functions that changed their signature from Studio 2003 to Studio 2005. Below are some screen shots of the wizard. 
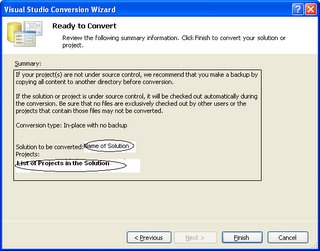
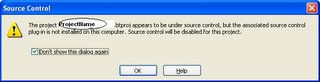
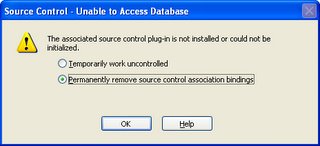
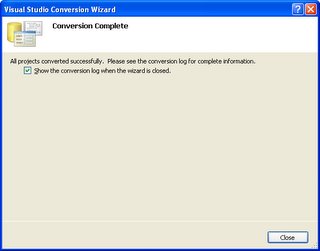

(This Final step gives the Migration Report)
BTW: Biztalk 2006 RTM is ready to roll!


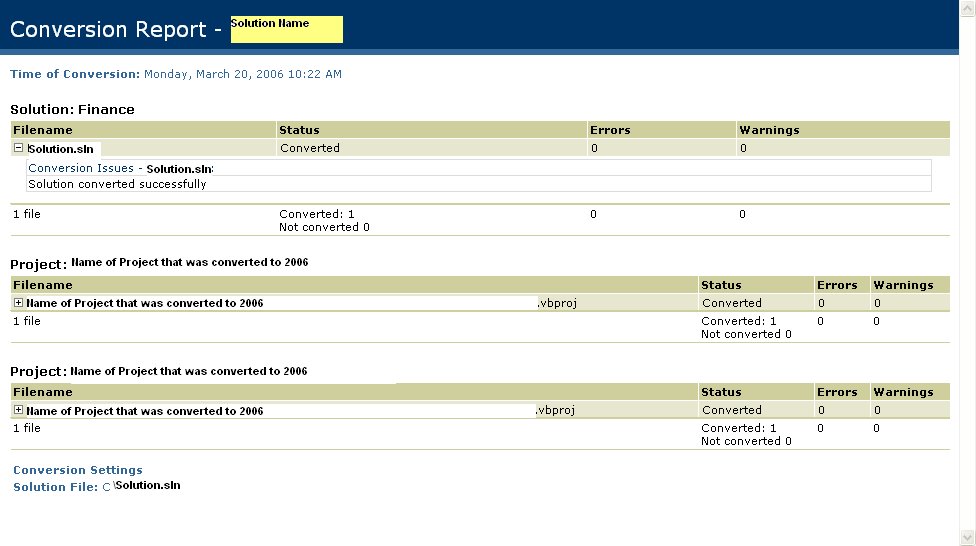
(This Final step gives the Migration Report)
BTW: Biztalk 2006 RTM is ready to roll!
Thursday, March 23, 2006
Coming soon!
I am in process of writing a research paper on Business Integration in general and how Biztalk positions itself in the grand schema of things.
Wednesday, March 22, 2006
Difference in HAT screens
I noticed that the HAT screen in 2006 is different than 2004. Actually there are certain functionalities that are absent in 2006. i.e "Operations" and "Configuration".
see below: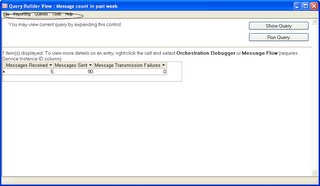
see below:
Trying to figure out as if how to terminate the "instances" in 2006 . In 2004 it was done by going to "Operations" and terminating the instances. Do not see anything similair in 2006 as for now. I think I have the answer, it can be done from Biztalk Admin Console
Tuesday, March 21, 2006
Some New Features in Biztalk 2006
Biztalk 2006 has some little changes here and there that can contribute to efficiency. Some of them are:
1) Having a "drop" down on the top pane of Solution Explorer window.
As in Biztalk 2004 version there was a horizontal scrolling to view all the artifacts contained in the solution. This was very frustrating at times because one could not see all the artifacts at once and needed to keep clicking to get to the right one. 2006 has a drop down that gives the list of all the artifacts at once and one can just click the required one.
1) Having a "drop" down on the top pane of Solution Explorer window.
As in Biztalk 2004 version there was a horizontal scrolling to view all the artifacts contained in the solution. This was very frustrating at times because one could not see all the artifacts at once and needed to keep clicking to get to the right one. 2006 has a drop down that gives the list of all the artifacts at once and one can just click the required one.

2) File adapter (recv and send) contains an option for authentication.
As in 2004 version, biztalk service account had to have full permissions on the shared drive that contains the receive or send folder. In 2006 it need not be. Any user name and password that has permissions to the shared drive can be used to access the shared driver from Biztalk Explorer. It need not be Biztalk service account. 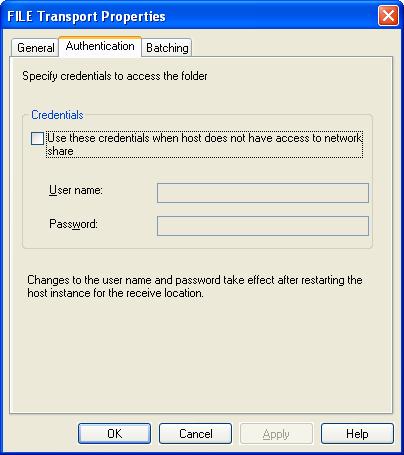
3) File Adapter Batching
The receive location has option of batching the incoming file. This option was not available in 2004.
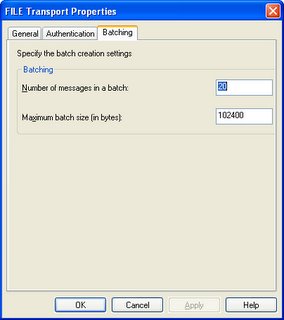
Thursday, March 16, 2006
Event Name: BizTalk Server 2006 First Look Clinic - Iselin, NJ
I registered for this seminar.
For interested people :
Session Code: 1032288971
Session Name: BizTalk Server 2006 for DevelopersSession
Location: Microsoft NJ Office/Long Beach Conference Room
Session Room:
Session City: IselinSession
Start Date: 04/04/06
For interested people :
Session Code: 1032288971
Session Name: BizTalk Server 2006 for DevelopersSession
Location: Microsoft NJ Office/Long Beach Conference Room
Session Room:
Session City: IselinSession
Start Date: 04/04/06
Tuesday, February 21, 2006
Secure FTP Adapter
Biztalk 2004 comes with out of box adapter for FTP. But if you want to transmit USING secure FTP then you need to install custom adapter. One of the recommended SFTP adapters by MSFT is from their partner /n Software. It is simple installation. Once the installation is done go to Biztalk Admin and click on Adapters. Then add New. Name it SFTP and then from the drop down "Adapter" chose the installed adapter.
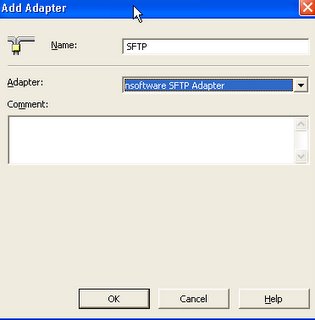
Now, when you go and create a new Send Port. Under the Transport Type you can see the option for new adapter SFTP. You can open the properties for URI and add the information as you will add for standard FTP.
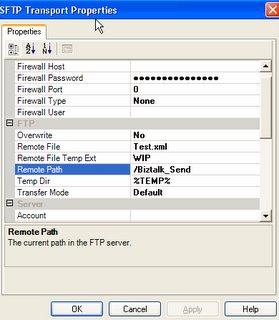
As far I know one of the drawbacks to this adapter is that it does not exposes its properties in Orchestration. I will dig deeper into this. If I can't access the properties in Orchestration then I can't use SFTP in a dynamic Port like I can use standard FTP.
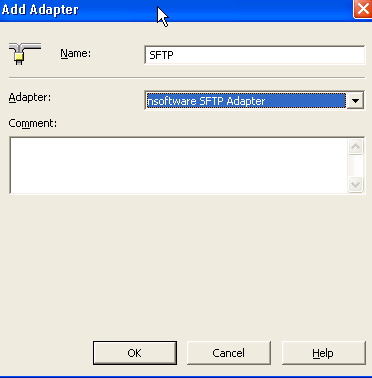
Now, when you go and create a new Send Port. Under the Transport Type you can see the option for new adapter SFTP. You can open the properties for URI and add the information as you will add for standard FTP.

As far I know one of the drawbacks to this adapter is that it does not exposes its properties in Orchestration. I will dig deeper into this. If I can't access the properties in Orchestration then I can't use SFTP in a dynamic Port like I can use standard FTP.
Thursday, January 26, 2006
Custom Pipeline Woes
In one of my project, the source system was sending 2 almost similar messages to Biztalk. The only difference was the root node name. I had 2 ways of dealing with it.
Solution 1:
1) Create separate document schemas
2) Create separate Receive Pipelines referring to each document schema
3) Use a map to change the root node name so to have exactly same message that can pass through the common orchestration thereafter.
Pros:
1) Less Development time
2) Easy message retrieving in case of failure
Cons:
1) Additional artifacts required in form of additional schemas and pipelines.
2) Low in performance and high in memory usage as we have to use extra map.
Solution 2:
Use a custom pipeline component that will replace the “root node” name to a common node name.
Pros:
1) Cleaner and Faster
Cons:
1) More development time
2) If error handling is not proper then the entire message is lost. This is because there is no persistence to messagebox in the pipelines.
Whereas the first solution is very easy, the second is relatively difficult. I tried the second one for simple reason that it was challenging and I thought I could do it within reasonable time that I had. I started by following the standard procedure for developing custom pipeline components. I used the “FixMsg” custom pipeline sample from “SDK” as my base code. It is located at “..\Program Files\Microsoft BizTalk Server 2004\SDK\Samples\Pipelines\CustomComponent”. This saved me some time in not “reinventing” the wheel. I worked on the “Execute” method and converted the Stream to Byte and then Byte to string. Then I tried replacing the required node in string and then tried to convert back the new string back to stream. Since pipeline only deals with streaming data. I ensured that the return is a “stream”. My approached looked quiet logical to me but the results were NADA. This string replacement did not actually work as I was not able to pass the “stream” back to the next stage of the pipeline. Then, I thought of using XPath. But since pipeline deal with streaming data whereas Xpath requires the whole message to be loaded into memory. I could not use the normal Xpath but I could “streaming Xpath”. This is called “forward only” Xpath. I tried “cloning” the stream so I can use XMLReader class on it. But could not go anywhere, then I gave up the solution as I was running out of time. I lost this challenge!! But, I will definitely revisit it once I get some “breathing space”.
Any inputs will be welcome.
Solution 1:
1) Create separate document schemas
2) Create separate Receive Pipelines referring to each document schema
3) Use a map to change the root node name so to have exactly same message that can pass through the common orchestration thereafter.
Pros:
1) Less Development time
2) Easy message retrieving in case of failure
Cons:
1) Additional artifacts required in form of additional schemas and pipelines.
2) Low in performance and high in memory usage as we have to use extra map.
Solution 2:
Use a custom pipeline component that will replace the “root node” name to a common node name.
Pros:
1) Cleaner and Faster
Cons:
1) More development time
2) If error handling is not proper then the entire message is lost. This is because there is no persistence to messagebox in the pipelines.
Whereas the first solution is very easy, the second is relatively difficult. I tried the second one for simple reason that it was challenging and I thought I could do it within reasonable time that I had. I started by following the standard procedure for developing custom pipeline components. I used the “FixMsg” custom pipeline sample from “SDK” as my base code. It is located at “..\Program Files\Microsoft BizTalk Server 2004\SDK\Samples\Pipelines\CustomComponent”. This saved me some time in not “reinventing” the wheel. I worked on the “Execute” method and converted the Stream to Byte and then Byte to string. Then I tried replacing the required node in string and then tried to convert back the new string back to stream. Since pipeline only deals with streaming data. I ensured that the return is a “stream”. My approached looked quiet logical to me but the results were NADA. This string replacement did not actually work as I was not able to pass the “stream” back to the next stage of the pipeline. Then, I thought of using XPath. But since pipeline deal with streaming data whereas Xpath requires the whole message to be loaded into memory. I could not use the normal Xpath but I could “streaming Xpath”. This is called “forward only” Xpath. I tried “cloning” the stream so I can use XMLReader class on it. But could not go anywhere, then I gave up the solution as I was running out of time. I lost this challenge!! But, I will definitely revisit it once I get some “breathing space”.
Any inputs will be welcome.
Tuesday, January 17, 2006
Capturing ACKs and NACKs
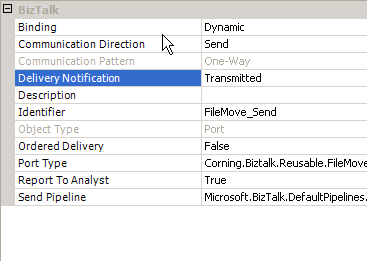
I am presently working on "File Mover" application. This application will replace existing VB application to move files from point A to point B based on the filename. Filename contains the send location address. I am populating a SQL database to track the file moved from point A to point B. One of the problems I am having is to capture the "Error in Transmission". This is tough to capture because File adapter transmission is separate from Orchestration process. Once orchestration is complete, it does not really care if message was sent or error out. For this we need to use concept of ACKs (Acknowledgements) and NACKs (Negative Acknowledgements). ACKs indicate successful message transmission and NACKs indicate failures in transmissions. Since I am using one way "asynchronous" FILE transmission these come handy. Some readers may ask why not use Request-Response. The reason is that they can only be used for HTTP adapter when there is a response that can be captured. For File adapter transmissions, we can only use ACKs and NACKs
Follow steps below and that is all you need to capture ACKs and NACKs.
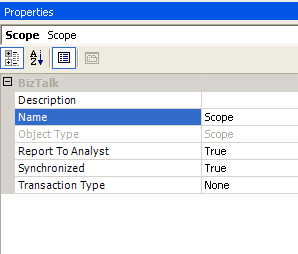
1) Put Send shape in a Scope and make "Transaction Type" as "None".
2) Set "Synchronized" property to "True".
3) Mark Orchestration with Delivery Notification = Transmitted
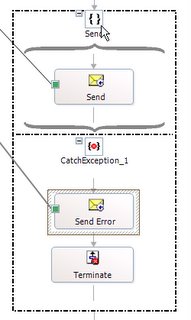
4) Use "Catch Exception shape"
5) Select the following exception type in properties:
"Microsoft.XLANGs.BaseTypes.DeliveryFailureException"
6) Call the insert method for populating database in the "Catch" shape.
8) Put the "Send" shape to save the "bad" files to a folder.
7) Then PUT the "terminate" shape in the "CATCH shape".
Follow steps below and that is all you need to capture ACKs and NACKs.
1) Put Send shape in a Scope and make "Transaction Type" as "None".
2) Set "Synchronized" property to "True".
3) Mark Orchestration with Delivery Notification = Transmitted
4) Use "Catch Exception shape"
5) Select the following exception type in properties:
"Microsoft.XLANGs.BaseTypes.DeliveryFailureException"
6) Call the insert method for populating database in the "Catch" shape.
8) Put the "Send" shape to save the "bad" files to a folder.
7) Then PUT the "terminate" shape in the "CATCH shape".


Wednesday, January 11, 2006
Wonderful Cruise!
The other day I was talking to one of my co worker (Abhi). He also maintains a Biztalk blog http://biztalkland.blogspot.com. We discussed about putting more non-technical stuff on the blob. We gave argument for and against it. How it will look out of place ...blah..blah. Finally, we decided that Blog is a medium to express. So there are no Rules for it as such. People might argue on this. Everyone is entitled to his/her opinion. After the conversation, I decided to trickle some personal stuff now and then.
I went on cruise with my wife. It was our "HoneyMoon" cruise. Even though it took place after 6 months of our marriage. I had just enough time to get married in June so we did not push for Honeymoon that time. Although we did went to India for our Reception as we got married in USA. After we came back she became busy with her residency and I went down with my project. Xmas and New Year stretch was good for the break we needed and we used that time to hop on a ship and hit the Caribbean. We went to San Juan, Saint Maartin and Saint Thomas. I personally loved Saint Thomas. The beaches are pristine there. We had tons of fun before coming back to Sub Zero temps. I am also putting some pics from our trip!



I went on cruise with my wife. It was our "HoneyMoon" cruise. Even though it took place after 6 months of our marriage. I had just enough time to get married in June so we did not push for Honeymoon that time. Although we did went to India for our Reception as we got married in USA. After we came back she became busy with her residency and I went down with my project. Xmas and New Year stretch was good for the break we needed and we used that time to hop on a ship and hit the Caribbean. We went to San Juan, Saint Maartin and Saint Thomas. I personally loved Saint Thomas. The beaches are pristine there. We had tons of fun before coming back to Sub Zero temps. I am also putting some pics from our trip!



Tuesday, January 03, 2006
FileMove Application and "MessageBox" error
Recently, I was asked to create an application that will replace an existing VB application. The application was to move the Files from a common location and drop them to a different destination based on the FileName. The File Name had the destination name in it. This is what I did:
1) Created a simple Orchestration with single receive port that will have filter for every possible file. i.e. pdf, dat, xml, txt etc.
2) Create a Dynamic port
3) Create a "Helper" class in VB.net. This will parse the incoming file name to extract the URI for dynamic port. This URI will determine where the file should be routed too.
I set up the whole project but found some interesting facts:
1) If the URI is blank for some reasons. You will get the following error in the eventvwr.
"Exception occured when persisting state to database".
2) The syntax for the URI for dynamic port will be.
file://servername/sharedfolder/Filename.
The start of the URI will tell the port that it is a "FILE" adapter. The rest will give the complete path to drop the file.
3) While using File.ReceiveFileName in the expression share. It will not only give the whole filename but also the path of the receive folder. In order to get the actual FileName, one will have to parse the whole path string.
1) Created a simple Orchestration with single receive port that will have filter for every possible file. i.e. pdf, dat, xml, txt etc.
2) Create a Dynamic port
3) Create a "Helper" class in VB.net. This will parse the incoming file name to extract the URI for dynamic port. This URI will determine where the file should be routed too.
I set up the whole project but found some interesting facts:
1) If the URI is blank for some reasons. You will get the following error in the eventvwr.
"Exception occured when persisting state to database".
2) The syntax for the URI for dynamic port will be.
file://servername/sharedfolder/Filename.
The start of the URI will tell the port that it is a "FILE" adapter. The rest will give the complete path to drop the file.
3) While using File.ReceiveFileName in the expression share. It will not only give the whole filename but also the path of the receive folder. In order to get the actual FileName, one will have to parse the whole path string.
Subscribe to:
Posts (Atom)

_511.gif)
_530.gif)

{kind=link}